|
 |
 |
 |
| Figure 1. Motion History Image for arm-stretching movement generated from image differences. | |||
| James Davis | Gary Bradski |
| MIT Media Lab | Intel Corporation, SC12-303 |
| E15-390, 20 Ames St. | 2200 Mission College Blvd. |
| Cambridge, MA 02139 USA | Santa Clara, CA 95052 USA |
| davis@media.mit.edu | gary.bradski@intel.com |
In earlier work (Davis 1997), a real-time computer vision representation of human movement known as a Motion History Image (MHI) was presented. The MHI is a compact template representation of movement originally based on the layering of successive image motions. The recognition method presented for these motion templates used a global moment feature vector constructed from image intensities, resulting in a token-based (label-based) matching scheme. Though this recognition method showed promising results using a large database of human movements, no method has yet been proposed to compute the raw motion information directly from the template without the necessity of labeling the entire motion pattern. Raw motion information may be favored for situations when a precisely labeled action is not possible or required. For example, a system may be designed to respond to leftward motion, but may not care if it was a person, hand, or car moving.
In this paper, we present an extension to the original motion template approach to now enable the computation of local motion information directly from the template. In this extension, silhouettes of the moving person are layered over time within the MHI motion template. The idea is that the motion template itself implicitly encodes directional motion information along the layered silhouette contours (similar to normal flow). Motion orientations can then be extracted by convolving image gradient masks throughout the MHI. With the resulting motion field, various forms of motion analysis and recognition are possible (e.g. matching histograms of orientations). To ensure fast and stable computation of this approach, we exploit the Intel Computer Vision Library (CVLib) procedures designed in part for this research. This software library has been optimized to take advantage of StrongArm and Pentium® MMX™ instructions. We offer the research presented in this paper both as a useful computer vision algorithm and as a demonstration of the Intel CVLib.
The remainder of this paper first examines the previous motion template
work (Section 2). Next, we present the approach of computing motion orientations
from a silhouette-based motion template representation (Section 3), along
with describing potential motion features and generalities of the approach.
We then present a brief overview of the Intel CVLib, the advantages resulting
from the CVLib enhancement in terms of vision processing, and its comparative
computational performance for this work (Section 4). We then summarize
results and conclusions (Section 5). Appendix A details the calculation
of moments and Hu moments used for the pose recognition approach for the
templates (Section 3.1.1).
|
|
|
|
|
| Figure 1. Motion History Image for arm-stretching movement generated from image differences. | |||
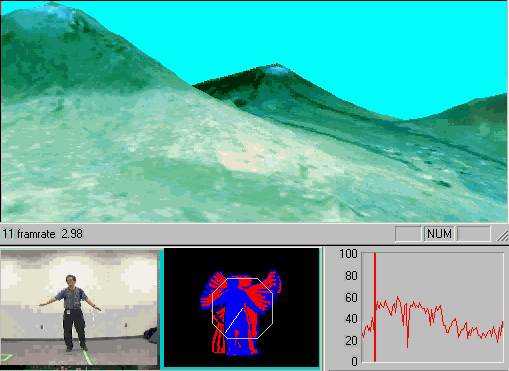
Already, interactive systems have been successfully constructed using the underlying motion template technology as a primary sensing mechanism. One example includes a virtual aerobics trainer (Davis 1998) that watches and responds to the user as he/she performs the workout (See Figure 2(a)). In this system, motion templates are used to watch and recognize the various exercise movements of the person, which in turn affects the response of the virtual instructor. Another application using the motion template approach is The KidsRoom (Bobick 1997). At one point in this interactive, narrative play space for children, virtual monsters appear on large video projection screens and teach the children how to do a dance. The monsters then dance with the children, complementing the kids whenever they perform the dance movements (See Figure 2(b)). The dancing movements of the children are recognized using motion templates. Thirdly, a simple interactive art demonstration can be constructed from the motion templates. By mapping different colors to the various time-stamps (or graylevels) within the MHI and displaying the result on a large projection screen, a person can have fun "body-painting" over the screen (See Figure 2(c)), reminiscent of Krueger-style interactive installations (Krueger 1991). Other applications in general that must be "aware" of the movements of the person (or people) could also benefit from using the motion template approach. For example, gesture-based computer video games (Freeman 1998) or immersive experiences (e.g. Hawaii flight simulator, as shown in Figure 2(d)) designed to respond to user gesture control could use the previous template approach or employ our new method as an additional sensing measurement or qualification of the persons movements. Even simpler gesture-based systems which rely on detecting characteristic motion (e.g. hand swipes to change a channel or a slide in a presentation) could profit from the fast and simple motion orientation features to be described.
Given the silhouettes extracted for constructing the MHI, we can also use the pose of the silhouette to give additional information about the action of the person. For example, we could use the pose to recognize the body configuration, and then use the motion information to qualify how the person moved to that position.
However, to indicate the discriminatory power of these moment features for the silhouette poses, we need only a few examples of each pose (at least sufficient for matrix inversion) to relate the distances between the classes.
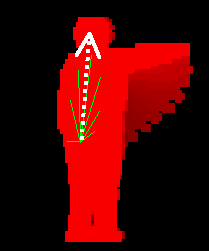
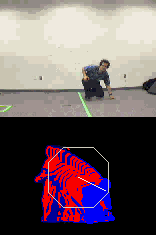
For this example, the training set consisted of 5 repetitions of 3 gestural poses ("Y", "T", and "Left Arm") shown in Figure 4 done by each of five people. A sixth person who had not practiced the gestures was brought in to perform the gestures. Table 1 shows the Mahalanobis distances for these new test poses Ti matched against the stored training models Pi . The table correctly shows that the true matches for the test poses (along the diagonal) have distances considerably smaller than to the other model poses in each row even though the first two poses, "Y" and "T", are fairly close to one another. This is a typical result showing that thresholds tend to be easy to set with distances between even fairly similar gestures ("Y" and "T") still about an order of magnitude apart. We next describe the MHI motion template representation (generated from successive silhouettes) used to extract the directional motion information.
 |
 |
 |
| Figure 4. Three example poses used for Mahalanobis distance measurements in Table 1. P1= "Y", P2= "T", and P3= "Left Arm". | ||
| P1 | P2 | P3 | |
| T1 | 14 | 204 | 2167 |
| T2 | 411 | 11 | 11085 |
| T3 | 2807 | 257 | 28 |
3.4 Motion Gradient
As shown in Figure 5(a) and (b), the local intensity gradients of the MHI directly yield the orientation of the silhouette contour motion. Hence, we can convolve classic intensity gradient masks with the MHI to compute the motion orientations. For the convolution, we used Sobel gradient masks:
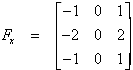 ,
, 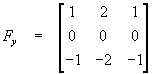 .
1.3
.
1.3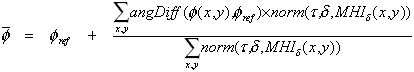 1.5
1.5It is intended that CVLib will eventually include functionality in the following areas:
| Un-optimized C | Optimized C | Optimized MMX Assembly |
| 22 frames/second | 27 frames/second | 30+ frames/second |
A video was recorded of a hand waving back and forth across the scene with a frequency of about one hertz. During the wave, the hand size fluctuated between taking up one to three quarters of the image. The video was two and a half minutes in duration. Intels VTUNE™ Performance Analyzer code was used to record the performance of the motion template gradient algorithm on this video sequence using both the optimized C
(PX) and assembly (A6) versions of CVLib. VTUNE™ rapidly samples the application and produces a report as to the percent of time spent in each module. Since optimized code runs faster, it might get called more often,
so we cant use total percent of time spent in PX vs. A6 as a comparison. Instead we have the situation as shown in Table 3.
| PX | A6 | |
| Motion Template Time | A | A/K |
| Time in rest of code | 1-A | 1-A |
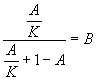 .
16
.
16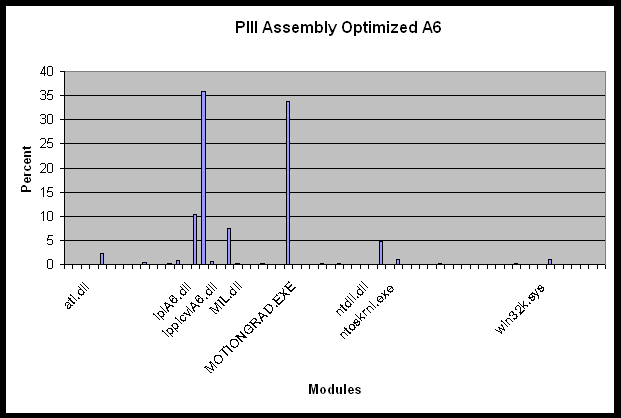
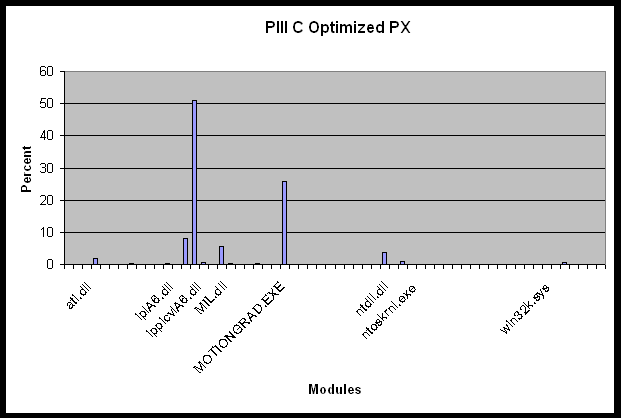
Given the methods described in this work and the overall functionality of the CVLib, many applications could benefit from the proposed methodology and implementation. Systems incorporating human movements for input must recognize and respond quickly to the user without noticeable lag to give a sense of immersion and control. The quickness of the characterization and its response is paramount. We believe that the motion template research, as optimized in CVLib, offers such a system.
To gain a better intuition of how to reason about moments
and get an insight into how to derive invariant features based on moments,
we next consider several low-order moments and describe their physical
meaning. The definition of the zero-th order moment, ![]() ,
of the image
,
of the image ![]() is
is
The two first order moments, ![]() ,
are used to locate the center of mass of the object. The center
of mass defines a unique location with respect to the object that may be
used as a reference point to describe the position of the object within
the field of view. The coordinates of the center of mass can be defined
through moments as shown below
,
are used to locate the center of mass of the object. The center
of mass defines a unique location with respect to the object that may be
used as a reference point to describe the position of the object within
the field of view. The coordinates of the center of mass can be defined
through moments as shown below
There are ten moments up to the 3rd order, but scale normalization and translation invariance fix three of these moments at constant values. Rotation invariance takes away one more degree of freedom leaving us with six independent dimensions. Hu uses seven variables however: six to span the six degrees of freedom, and a final seventh variable whos sign removes reflection invariance. Only the first six of the Hu variables below give reflection invariance.
The seven moment-based features proposed by Hu that are functions of normalized moments up to the third order are:
![]()
![]()
![]()
![]()
![]()
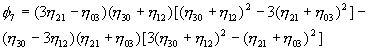
Akita, K. Image sequence analysis of real world human motion. Pattern Recognition, 17, 1984.
Bergen, J., Anandan, P., Hanna, K., and R. Hingorani. Hierarchical model-based motion estimation. In Proc. European Conf. on Comp. Vis., pages 237-252, 1992.
Black, M. and P. Anandan. A frame-work for robust estimation of optical flow. In Proc. Int. Conf. Comp. Vis., pages 231-236, 1993.
Bobick, A., Davis, J., and S. Intille. The KidsRoom: an example application using a deep perceptual interface. In Proc. Perceptual user Interfaces, pages 1-4, October 1997.
Bradski, G., Yeo, B-L. and M. Yeung. Gesture for video content navigation. In SPIE99, 3656-24 S6, 1999.
Bradski, G. Computer Vision Face Tracking For Use in a Perceptual User Interface. In Intel Technology Journal, http://developer.intel.com/technology/itj/q21998/articles/art_2.htm, Q2 1998.
Braun, M. Picturing time: The work of Etienne-Jules Marey (1830-1904). University of Chicago Press, 1992.
Bregler, C. Learning and recognizing human dynamics in video sequences. In Proc. Comp. Vis. And Pattern Rec., pages 568-574, June 1997.
Capelli, R. Fast approximation to the arctangent. Graphics Gems II, Academic Press, James Arvo Editor, pages 389-391, 1991.
Cedras, C. and M. Shah. Motion-based recognition: a survey. Image and Vision Computing, Vol. 13, Num 2, pages 129-155, March 1995.
Cham, T. and J. Rehg. A multiple hypothesis approach to figure tracking. In Proc. Perceptual User Interfaces, pages 19-24, November 1998.
Cuttler, R. and M. Turk. View-based interpretation of real-time optical flow for gesture recognition. Int. Conf. On Automatic Face and Gesture Recognition, page 416-421, 1998.
Darrell, T., Maes, P., Blumberg, B., and A. Pentland. A novel environment for situated vision and behavior. In IEEE Wkshp. For Visual Behaviors (CVPR), 1994.
Davis, J. Recognizing movement using motion histograms. MIT Media lab Technical Report #487, March 1999.
Davis, J. and A. Bobick. Virtual PAT: a virtual personal aerobics trainer. In Proc. Perceptual User Interfaces, pages 13-18, November 1998.
Davis, J. and A. Bobick. A robust human-silhouette extraction technique for interactive virtual environments. In Proc. Modelling and Motion capture Techniques for Virtual Environments, pages 12-25, 1998.
Davis, J. and A. Bobick. The representation and recognition of human movement using temporal templates. In Proc. Comp. Vis. and Pattern Rec., pages 928-934, June 1997.
Edgerton, H. and J. Killian. Moments of vision: the stroboscopic revolution in photography. MIT Press, 1979.
Freeman, W., Anderson, D., Beardsley, P., et al. Computer vision for interactive computer graphics. IEEE Computer Graphics and Applications, Vol. 18, Num 3, pages 42-53, May-June 1998.
Freeman, W., and M. Roth. Orientation histograms for hand gesture recognition. In Intl Wkshp. On Automatic Face- and Gesture-Recognition, 1995.
Gavrila, D. The visual analysis of human movement: a survey. Computer Vision and Image Understanding, Vol. 73, Num 1, pages 82-98, January, 1999.
Haritaoglu, I. Harwood, D., and L. Davis. W4S: A real-time system for detecting and tracking people in 2 ½ D. European. Conf. On Comp. Vis., pages 877-892, 1998.
Hogg, D. Model-based vision: a paradigm to see a walking person. Image and Vision Computing, Vol. 1, Num. 1, 1983.
Horn, B. Robot Vision. MIT Press, 1986.
Horprasert, T. Haritaoglu, I., Harwood, D., et al. Real-time 3D motion capture. In Proc. Perceptual User Interfaces, pages 87-90, November 1998.
Hu, M. Visual pattern recognition by moment invariants. IRE Trans. Information Theory, Vol. IT-8, Num. 2, 1962.
Jain, R. and H. Nagel. On the analysis of accumulative difference pictures from image sequences of real world scenes. IEEE Trans. On Pattern Analysis and Machine Intelligence, Vol. 1, Num. 2, April 1979.
Ju, S., Black, M., and Y. Yacoob. Cardboard people: a parameterized model of articulated image motion. Int. Conference on Automatic Face and Gesture Recognition, pages 38-44, 1996.
Krueger, M. Artificial reality II, Addison-Wesley, 1991.
Little, J., and J. Boyd. Describing motion for recognition. In International Symposium on Computer Vision, pages 235-240, November 1995.
Moeslund, T. Summaries of 107 computer vision-based human motion capture papers. University of Aalborg Technical Report LIA 99-01, March 1999.
Moeslund, T. Computer vision-based human motion capture a survey. University of Aalborg Technical Report LIA 99-02, March 1999.
Pinhanez, C. Representation and recognition of action in interactive spaces. MIT Media Lab Ph.D. Thesis, June 1999.
Pinhanez, C., Mase, K., and A. Bobick. Interval scripts: a design paradigm for story-based interactive systems. Conference on Human Factors in Computing Systems, pages 287-294, 1997.
Polana, R. and R. Nelson. Low level recognition of human motion. In IEEE Wkshp. On Nonrigid and Articulated Motion, 1994.
Rohr, K. Towards model-based recognition of human movements in image sequences. CVGIP, Image Understanding, Vol. 59, Num 1, 1994.
Shah, M. and R. Jain. Motion-Based Recognition. Kluwer Academic , 1997.
Therrien, C. Decision Estimation and Classification. John Wiley and Sons, Inc., 1989.
Wren, C., Azarbayejani, A., Darrell, T., and A. Pentland. Pfinder: real-time tracking of the human body. SPIE Conference on Integration Issues in Large Commercial Media Delivery Systems, 1995.
Yamato, J., J. Ohya, and K. Ishii. Recognizing human action in time sequential images using hidden markov models. In Proc. Comp. Vis. and Pattern Rec., 1992.
Assembly optimized performance libraries in Image Processing, Signal Processing, JPEG, Pattern Recognition and Matrix math are at http://developer.intel.com/vtune/perflibst/.